翻譯自 這裡
Input and Output :
這裡將介紹 Python 的 IO 操作, 包括顯示訊息到 Console 與 檔案操作等.
Fancier Output Formatting :
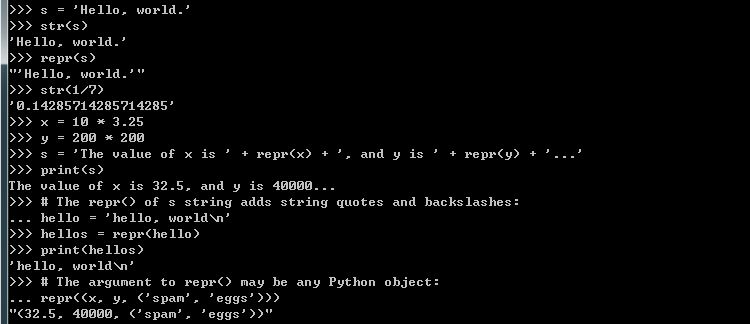
到目前為止我們都是使用函式 print() 來將訊息輸出到 Console. 有時你可能希望能針對輸出進行類似其他語言 printf() 的功能, 幸運的是 Python 的 string 物件本身就提供類似的函式如str.format(). 透過他你可以使用類似 printf() 的功能. 接著你可能會遇到如何將其他物件轉成 string 物件, 則可以使用函式 repr() 或 str(). 至於這兩個函式使用差別可以參考下面說明 :
底下為範例說明 :
底下是兩種輸出 squares and cubes 表格方式 :
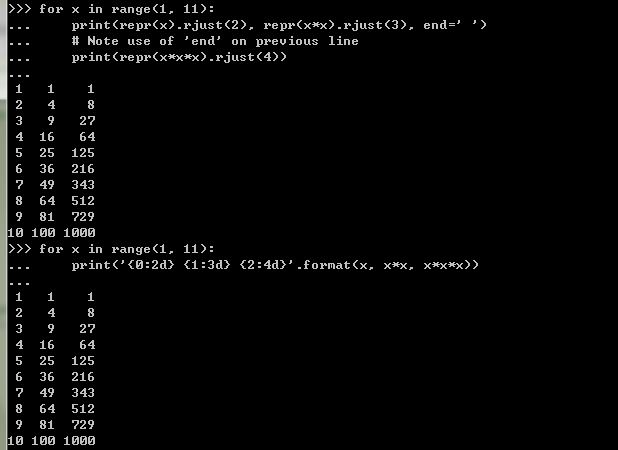
上面用到一個不錯的函式 str.rjust(), 你可以將輸出文字向右靠齊並設定 column 的寬度為某個長度. 事實上類似的還有 str.ljust() (向左靠齊) 與 str.center() (置中). 當你的實際字串比設定的 column 寬度還要大時, 則字串會原封不動的輸出, 並不會有 truncation 發生. 還有一個實用的函式 str.zfill(), 他可以把你不夠的位數補 0 :
底下是字串函式 str.format() 用法 :
str.format() 用法也可以結合key/value pair :
'!a' (apply ascii()), '!s' (apply str()) and '!r' (apply repr()) can be used to convert the value before it is formatted :
另外你可以使用 ':' 將數字格式做更細緻的設定 :
另外 ':' 可以用來設定欄位的寬度, 在製作表格時會很方便 :
上面的用法透過 ‘**’ 可以更簡潔 :
其實更早 Python 版本是使用 '%' 來達到上述的功能. 底下是官網對這兩個用法定位的說明 :
- Old string formatting
這邊稍微提一下舊版本的 Python 是使用 % 運算子來模擬類似 sprintf()-style format. 底下為其範例說明 :
Reading and Writing Files :
我們使用函式 open() 來開啟檔案, 該函式會返回一個 file object. 並且通常該函式使用會用到兩個參數 open(filename, mode) :
由上可以知道第一個參數為檔案路徑, 第二個參數為操作模式 :
預設檔案打開是使用 text mode, 讀寫檔案預設使用 UTF-8 encoding. 另外有 Platform dependency 的換行 (\n on Unix, \r\n on Windows) 也會被統一成 '\n'. 這個行為對 binary mode 有可能會造成 corrupt, 使用上要特別注意.
- Methods of File Objects
底下的範例操作會假設你已經開啟一個文件並以變數 f 作為你的 file object. 首先你可以使用 f.read(size) 來讀取檔案內容, 如果沒有給參數 size 或是 size 為負值則會讀出檔案所有內容並返為一個 string 或 bytes 物件. 如果 size 為正數, 則會讀取 size bytes 的內容, 如果已經讀到檔案結尾, 則會返回空字串 '' :
如果你想一次讀一行內容, 你可以使用函式 f.readline(). 要注意的是每一行的換行字元 '\n' 還是會被讀進來 (除了最後一行外). 一樣的是如果你已經讀到檔案結尾, 接著讀出來的會是空字串 :
如果要將檔案讀出並一行行存放在串列中, 可以使用 f.readlines(), 它提供一個參數 sizehint 讓你可以決定讀出內容最多不超過指定大小, 但是讀出來的行並不會被 truncate. 通常用在讀大檔案時 :
另外你也可以使用 for loop 一行行讀出檔案內容 (因為 end='', 此時換行符號為檔案中的換行而不會有 print() 函式的換行) :
如果要寫資料到檔案, 可以使用函式 f.write(string). 返回值為寫了多少 bytes 到檔案 :
要注意的是如果你要寫到檔案的物件不是 string, 請先使用 str() 函式轉換 (否則會出現 TypeError) :
使用函式 f.tell() 可以讓你知道目前指標在檔案的哪個位置 (目前讀了多少 bytes). 如果你要變更指標位置可以使用函式 f.seek(offset, from_what). offset 是從參數 from_what 開始計算, 另外在 text mode 你只能使用 from_what=0 (唯一的例外就是可以使用 f.seek(0,2) 跳到檔案結尾處, 否則會出現 io.UnsupportedOperation:). 底下是參數 from_what 說明 :
範例說明 :
如果你要關閉檔案讀寫可以使用 f.close() :
另外你可以使用關鍵字 with 在你離開程式或是發生 exception 時自動幫你關閉開啟的 io. 類似的功能也可以使用 try-finally 完成 :
file object 還可使用函式 isatty() 與 truncate(). 用法可以到 Library Reference 找到詳細說明.
- The pickle Module
前面說明我們知道使用 file object 的函式 write() 必須傳入 string 物件, 也就是說如果你要寫入其他物件如 tuple, 字典物件或串列, 則必須進行轉換. 在 Python 提供標準模組 pickle 來幫你將物件轉換成對應 string 物件的映射關係, 這樣的動作稱為 pickling ; 甚至透過剛剛建立的 string 物件映射, 你可以重建原來的物件, 這樣的動作稱為 unpickling. 透過這樣的動作你可以將物件存放在檔案或是在網路中傳遞. 假設你有一個物件 x ; 以及一個 file object 的變數 f, 則你可以如下將物件 x 寫到 f 中 :
如果你要從 f 中載回原物件, 則可以如下操作 :
底下是官網對該模組的簡介 :
Input and Output :
這裡將介紹 Python 的 IO 操作, 包括顯示訊息到 Console 與 檔案操作等.
Fancier Output Formatting :
到目前為止我們都是使用函式 print() 來將訊息輸出到 Console. 有時你可能希望能針對輸出進行類似其他語言 printf() 的功能, 幸運的是 Python 的 string 物件本身就提供類似的函式如str.format(). 透過他你可以使用類似 printf() 的功能. 接著你可能會遇到如何將其他物件轉成 string 物件, 則可以使用函式 repr() 或 str(). 至於這兩個函式使用差別可以參考下面說明 :
底下為範例說明 :
底下是兩種輸出 squares and cubes 表格方式 :
上面用到一個不錯的函式 str.rjust(), 你可以將輸出文字向右靠齊並設定 column 的寬度為某個長度. 事實上類似的還有 str.ljust() (向左靠齊) 與 str.center() (置中). 當你的實際字串比設定的 column 寬度還要大時, 則字串會原封不動的輸出, 並不會有 truncation 發生. 還有一個實用的函式 str.zfill(), 他可以把你不夠的位數補 0 :
底下是字串函式 str.format() 用法 :
str.format() 用法也可以結合key/value pair :
'!a' (apply ascii()), '!s' (apply str()) and '!r' (apply repr()) can be used to convert the value before it is formatted :
另外你可以使用 ':' 將數字格式做更細緻的設定 :
另外 ':' 可以用來設定欄位的寬度, 在製作表格時會很方便 :
上面的用法透過 ‘**’ 可以更簡潔 :
其實更早 Python 版本是使用 '%' 來達到上述的功能. 底下是官網對這兩個用法定位的說明 :
- Old string formatting
這邊稍微提一下舊版本的 Python 是使用 % 運算子來模擬類似 sprintf()-style format. 底下為其範例說明 :
Reading and Writing Files :
我們使用函式 open() 來開啟檔案, 該函式會返回一個 file object. 並且通常該函式使用會用到兩個參數 open(filename, mode) :
由上可以知道第一個參數為檔案路徑, 第二個參數為操作模式 :
預設檔案打開是使用 text mode, 讀寫檔案預設使用 UTF-8 encoding. 另外有 Platform dependency 的換行 (\n on Unix, \r\n on Windows) 也會被統一成 '\n'. 這個行為對 binary mode 有可能會造成 corrupt, 使用上要特別注意.
- Methods of File Objects
底下的範例操作會假設你已經開啟一個文件並以變數 f 作為你的 file object. 首先你可以使用 f.read(size) 來讀取檔案內容, 如果沒有給參數 size 或是 size 為負值則會讀出檔案所有內容並返為一個 string 或 bytes 物件. 如果 size 為正數, 則會讀取 size bytes 的內容, 如果已經讀到檔案結尾, 則會返回空字串 '' :
如果你想一次讀一行內容, 你可以使用函式 f.readline(). 要注意的是每一行的換行字元 '\n' 還是會被讀進來 (除了最後一行外). 一樣的是如果你已經讀到檔案結尾, 接著讀出來的會是空字串 :
如果要將檔案讀出並一行行存放在串列中, 可以使用 f.readlines(), 它提供一個參數 sizehint 讓你可以決定讀出內容最多不超過指定大小, 但是讀出來的行並不會被 truncate. 通常用在讀大檔案時 :
另外你也可以使用 for loop 一行行讀出檔案內容 (因為 end='', 此時換行符號為檔案中的換行而不會有 print() 函式的換行) :
如果要寫資料到檔案, 可以使用函式 f.write(string). 返回值為寫了多少 bytes 到檔案 :
要注意的是如果你要寫到檔案的物件不是 string, 請先使用 str() 函式轉換 (否則會出現 TypeError) :
使用函式 f.tell() 可以讓你知道目前指標在檔案的哪個位置 (目前讀了多少 bytes). 如果你要變更指標位置可以使用函式 f.seek(offset, from_what). offset 是從參數 from_what 開始計算, 另外在 text mode 你只能使用 from_what=0 (唯一的例外就是可以使用 f.seek(0,2) 跳到檔案結尾處, 否則會出現 io.UnsupportedOperation:). 底下是參數 from_what 說明 :
範例說明 :
如果你要關閉檔案讀寫可以使用 f.close() :
另外你可以使用關鍵字 with 在你離開程式或是發生 exception 時自動幫你關閉開啟的 io. 類似的功能也可以使用 try-finally 完成 :
file object 還可使用函式 isatty() 與 truncate(). 用法可以到 Library Reference 找到詳細說明.
- The pickle Module
前面說明我們知道使用 file object 的函式 write() 必須傳入 string 物件, 也就是說如果你要寫入其他物件如 tuple, 字典物件或串列, 則必須進行轉換. 在 Python 提供標準模組 pickle 來幫你將物件轉換成對應 string 物件的映射關係, 這樣的動作稱為 pickling ; 甚至透過剛剛建立的 string 物件映射, 你可以重建原來的物件, 這樣的動作稱為 unpickling. 透過這樣的動作你可以將物件存放在檔案或是在網路中傳遞. 假設你有一個物件 x ; 以及一個 file object 的變數 f, 則你可以如下將物件 x 寫到 f 中 :
如果你要從 f 中載回原物件, 則可以如下操作 :
底下是官網對該模組的簡介 :
This message was edited 38 times. Last update was at 13/01/2012 18:56:46


沒有留言:
張貼留言