Your code, your responsibility...your bug, your reputation!
When things get tough, it’s up to you to bring them back from the brink. Bugs, whether they’re in your code or just in code that your software uses, are a fact of life in software development. And, like everything else, the way you handle bugs should fit into the rest of your process. You’ll need to prepare your board, keep your customer in the loop, confidently estimate the work it will take to fix your bugs, and apply refactoring and prefactoring to fix and avoid bugs in the future.
Previously On :
You’d added Mercury Meals’ code into Orion’s Orbits and were all set to demo things to the CFO when you hit a problem. Well, actually three problems—and that adds up to one big mess...
- Orion’s Orbits is NOT working
Your customer added three new user stories that relied on some new code from Mercury Meals. Everything looked good, the board was balanced and you completed the integration work when, BOOM!, you ran your code and absolutely nothing happened. The application just froze...

- You have a LOT of ugly new code
When you dug into the new code, you found a ton of problems. What’s causing the problems in Orion’s Orbits, and where should you start looking?
- You have THREE user stories that rely on your code working.
All of this would be bad enough, but there are three user stories that rely on the Mercury Meals code working, not just one. To make matters even worse, the CEO of Orion’s Orbits has talked you up to the CFO, and both are looking forward to seeing everything working, and soon...

Let's get start :
First, you’ve got to talk to the customer...Whenever something changes, talk it over with your team. If the impact is significant, in terms of functionality or schedule, then you’ve got to go back to the customer. And this is a big issue, so that means making a tough phone call...
Before calling customer, you need to get things to a point where you can make a confident estimate as to how long this mess will take to fix..and get that estimate FAST. And firstly, you’re going to have to maintain this stuff so the best first step would be to get all the Mercury Meals code into your code repository and building correctly before we can even start to fix the problem.
Crux :
Below are some suggestions of To-Do-List :
Priority one: get things buildable :
The code is in version control now, you’ve written build scripts, and you’ve added continuous integration with CruiseControl. Mercury Meals is still a junky piece of nonworking code, but at least you should have a little bit of control over the code...and that’s your first priority.
- A little time now can save a LOT of time later
None of the original bugs are fixed just yet, but that’s OK. You’ve got a development environment set up, your code’s under version control, and you can easily write tests and run them automatically. In other words, you’ve just prevented all the problems you’ve seen over the last several hundred pages from sneaking up and biting you in the ass.
You know that the code doesn’t work, but now that everything is dialed into your process, you’re ready to attack bugs in a sensible way. You’ve taken ownership of the Mercury Meals code, and anything you fix from here on out will stay fixed...saving you wasted time on the back end.
Crux :
We could fix code now :
Now it’s time to figure out what needs to be fixed. Below are some hints on how to refactor your code :

But things might not be quite as bad as they look. You don’t have to fix all the bugs in Mercury Meals; you just have to fix the bugs that affect the functionality that you need. Don’t worry about the rest of the code—focus just on the functionality in your user stories.
Crux :
Below are some bullet points while refactoring old codes :
You know that Orion’s Orbits was working fine until you integrated the Mercury Meals library, so let’s focus on that code. The first step is to find out what’s actually working, and that means tests. Remember, if it’s not testable, assume it’s broken.
- Figure out how the function works or the working flow
In the beginning, it is great to probe your codes and figure out the working flow on how to accomplish a specific tasks/jobs. Take this case for example, we know there are two interfaces for use to carry out a task of ordering a meal :
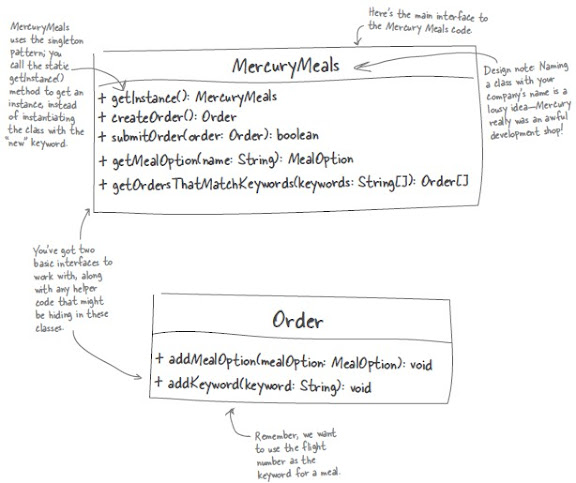
- Based on working flow, write Test case for each User story
In order to make sure the User story is workable, we have to create Test cases for each User story. So everytime when we have modification on the source codes, we can know if the codes work well or any side effect occurs (Regress test). Also we need a way to validate the User story among the codes.

Spike test to estimate :
30% of the tests you wrote are failing, but you really have no idea if a single line of code would fix most of that, or if even passing one more test could take new classes and hundreds of lines of code. There’s no way to know how big a problem those 13 test failures really represent. So what if we take a little time to work on the code, see what we can get done, and then extrapolate out from that?
This is called spike testing: you’re doing one burst of activity, seeing what you get done, and using that to estimate how much time it will take to get everything else done. Below are the possible steps for your reference :
1. Take a week to conduct your spike test
Get the customer to give you five working days to work on your problem. That’s not a ton of time, and at the end, you should be able to supply a reasonable estimate.
2. Pick a random sampling from the tests that are failing
Take a random sample of the tests that are failing, and try to fix just those tests. But be sure it’s random—don’t pick just the easy tests to fix, or the really hard ones. You want to get a real idea of the work to get things going again.
3. At the end of the week, calculate your bug fix rate
Look at how fast you and your team are knocking off bugs, and come up with a more confident estimate for how long you think it will take to fix all the bugs, based on your current fix rate :

Your tests gave you an idea as to how much of your code was failing. With the results of your spike test, you should have an idea about how long it will take to fix the remaining bugs :

You can then figure out how long it will take for your team to fix all the bugs :

- When it comes to bug fixing, we really can’t be sure
When it comes down to it, a spike test really only gives you a more accurate estimate than a pure guess. It’s not 100% accurate, and may not even be close. But the spike test does give you quantitative data upon which you can base your estimates. You know how many bugs you fixed, and it was a random sample, so you can say with a certain degree of confidence that you should be able to fix the same number of further bugs in roughly the same amount of time.
- Your team’s gut feeling matters
One quick way that you can add some qualitative feedback into your bug fix estimate is by factoring in the confidence of your team. During the spike test week, you’ve all have seen the Mercury Meals code, probably in some depth, so now’s the time to run your fix rate past your team to factor in their confidence in that number :

Take the average of your team’s confidence, in this case 70% ((60%+70%+80%)/3), and factor that into your estimate to give you more confidence :

- Give your customer the bug fix estimate
You’ve got an estimate you can be reasonably confident in, so head back to the customer. Tell him how long it will take to fix the bugs in the Mercury Meals code, and see if you can get fixing.
Extra works to do :
There are some works may be related to the bug fixing, such as documentation, dependencies check. It all depends on the real situation whether to do it or not. Below are some suggestions on would you do this now and why :
- Figure out what dependencies this code has and if it has any impact on Orion’s Orbits’ code.
- Figure out how to package the compiled version to be included in Orion’s Orbits.
- Document the code.
- Run a coverage report to see how much code you may need to fix.
- Get a line count of the code and estimate how long it will take to fix.
- Do a security audit on the code.
- Use a UML tool to reverse-engineer the code and create class diagrams.
Finish the iteration successfully :
You’ve reached the end of this iteration and, by managing the work and keeping the customer involved, you’ve successfully overcome the Mercury Meals bug nightmare. Most importantly, you’ve developed what your customer needed.
- Burned Down Rate

- Next Iteration

- Completed

Tools for your Software Development Toolbox :
Software Development is all about developing and delivering great software. In this chapter, you learned how to debug like a pro.



沒有留言:
張貼留言